wanx-troopers
Wan Motion Tricks
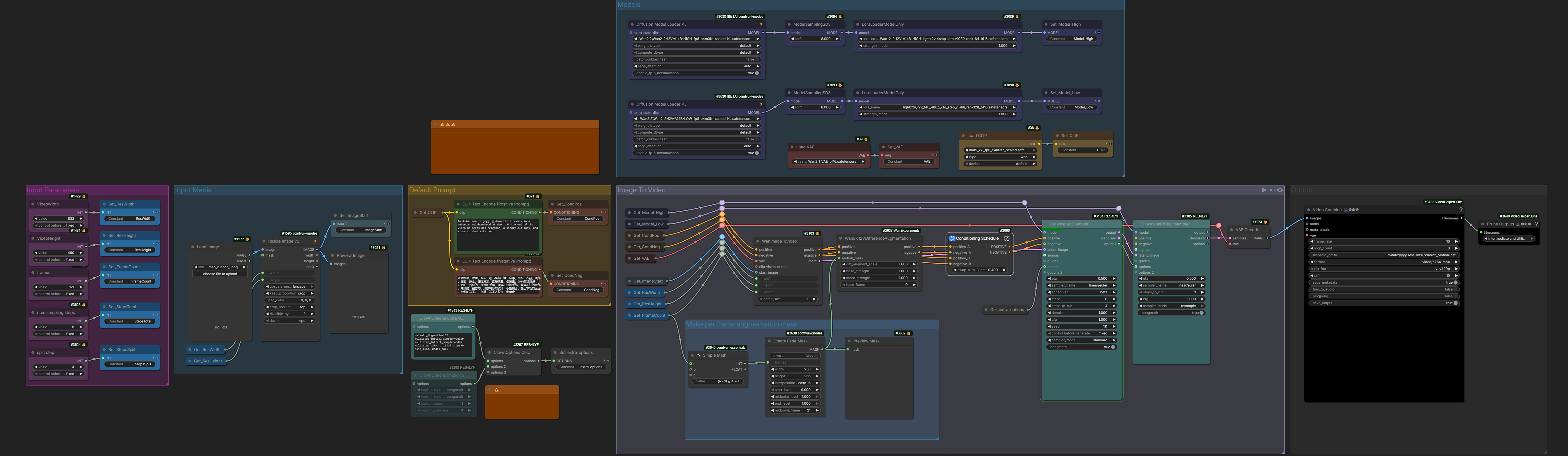
Scale Rope
Scale Rope is a ComfyUI native node which provides access to set several parameters of “RoPE function”.
It is a full exact equivalent of WanMotionScale community node treding on reddit end of 2025
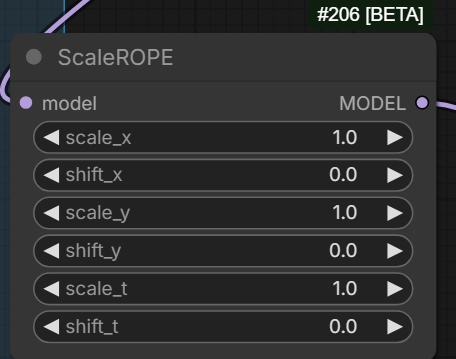
WanVideo RoPE Function is a Wrapper equivalent - though please note that values are set a bit differently
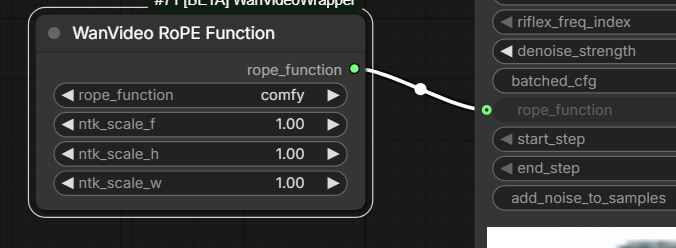
Scale values are the parameters more useful to experiment with:
it’s basically like telling the model these 81 frames are actually 40 frames and so on, in the wrapper it’s done bit differently and the logic is inverse to the comfy core way of doing it (which the “WanMotionScale” node is identical to)
Shift parameters are
not that useful … just mess up the relation of frames to rope positional ids
for spatial dimensions it’s the only way to break the repetition when going past certain point, which is the main reason the node exists; riflex also did something similar for temporal btw
See the next section UltraVico for an alternative. A word of warning for both sections:
scaling the rope will definitely lead to unwanted behaviour and often ruined motion as well; most notable thing that played with temporal rope scaling is riflex… and it never worked great with Wan
UltraVico
UltraVico is the modern implementation of RifleX
method for generating longer videos which was discussed on Reddit around summer of 2025.
It is a way to “convince” Wan 14B models to generate videos longer that 81 frames without looping.
Pls. heed the warning at the end of the previous section ^.
sageattn_ultravico is an attention_mode which can be chosen on WanVideoModelLoader in Wrapper.
It does seem that activating it may require having a working installation of SageAttention, probably one of 2.x ones.
Success has been demonstrated both on Kandinsky-5 and on Wan 2.2, high noise.
you can now also set it for specific steps with this; first step most important of course
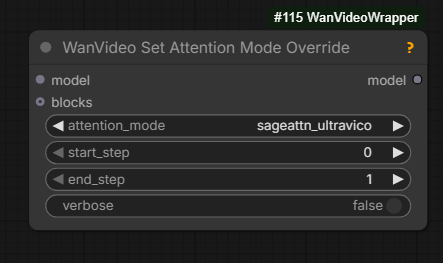
intended for t2v; harder to use with I2V; it decays the part of the sequence that has the image conditioning, so you lose that… unless you use higher alpha and don’t allow as much decay, but then it can’t really get away from the start image, creating same initial issue of long I2V: it just loops; it doesn’t loop as badly, but still does … the old man never jumps to the water until alpha is 0.91 or so
Only tested on high noise.
UltraVico is an alternative to Scale Rope discussed above.
UltraVico Obscure Conversations
During the testing of UltraVico different implementation was tried.
The alternative implementation provided ability to tweak parameters which were there called “alpha, beta, gamma”.
These parameters are not exposed by the main implementation in Wrapper. Just documenting what was found
0.95 alpha, 0.3 beta, 4 gamma
0.95 alpha for ultravico doesn’t really allow the subject to leave the frame :/
Painter I2V
2025.12.04
augment_empty_frames parameter added to WanVideo ImageToVideo Encode node in Wrapper
provides a full and equivalent replacement for Painter I2V implemented natively inside the Wrapper:
A replacement for native and ClowShark worflows also exists in
GH:drozbay/WanExperiments repository.
WanEx_PainterMotionAmplitude allows to do Painter I2V-style
trick in regular workflows, e.g. it makes Painter I2V approach modular.
The node generates positive/negative conditioning that can be connected to sampler nodes using I2V family
of Wan video generation models. It should work with both native KSampler and the ClowShark one, but not with the Wrapper.
Painter I2V Summary
princepainter/PainterI2V node attracted attention and sparked research. It exists into two versions
The node was created to inject more motion into I2V generations with speed LoRa-s. It works by preparing noise latents in a special manner.
Here are some quotes about it: “It’s pre-scaling the input latents”; “it tries to balance out the brightness increase you normally get when scaling the input like that”; “basically adding some of the input image to what’s normally gray in I2V input”; “I think the logic behind using the reference partially in those frames is to keep the color from changing”; “this is what it does to input image: invert and blend to gray” (input latents); “definitely changes something” - “thing is it’s randomness, if you added noise controllably then you could also make a slider that changes the output”
Apparently the node subtracts the initial image from initial noise on all frames. While this does change the end result of generation the change can be both positive and negative.
Painter FLF2V
Same GitHub account, now an FLF node: link
PainterLongVideo
GH:princepainter/ComfyUI-PainterLongVideo from that same authrow is being played with. Expert conclusion however is that the node is either simply an automation I2V extension via last frame or possibly also Painter I2V on top of it.
looking closer at PainterLongVideo and the code just … only one part that attempts to use multiple frames from the previous video, and it feeds that into a conditioning parameter called “reference_motion”, which is … only ever used by the Wan S2V model; other than that it appears to be just standard last frame to first frame continuation with the PainterI2V motion amplitude added in
PainterI2Vadvanced
GH:princepainter/ComfyUI-PainterI2Vadvanced is making bold claims about color correction, but this node prepares inputs for sampling so it cannot possibly be fixing outputs
Drozbay’s Augmentation For Longer Videos
Inspired by Painter I2V approach to boosting motion Drozbay has created one extra tool to generate longer videos with Wan 2.2 I2V without looping