Musubi Tuner just received K5 Pro support.
List of current speed-ups: “T2V 5s distill with Easy Cache and Sage Attention v1” + “NABLA patch (PR# 11371)”.
not the way of doing things in comfy, there’s attention patch mechanic that should be used
NABLA node is apparently present in Kijai’s Wrapper repo, uses torch compile ??
Waiting for PR 11371 to be merged in adding/restoring Nabla attention for 10sec K5, 2.7x speedup.
Distilled Kandinsky-5 versions have become available
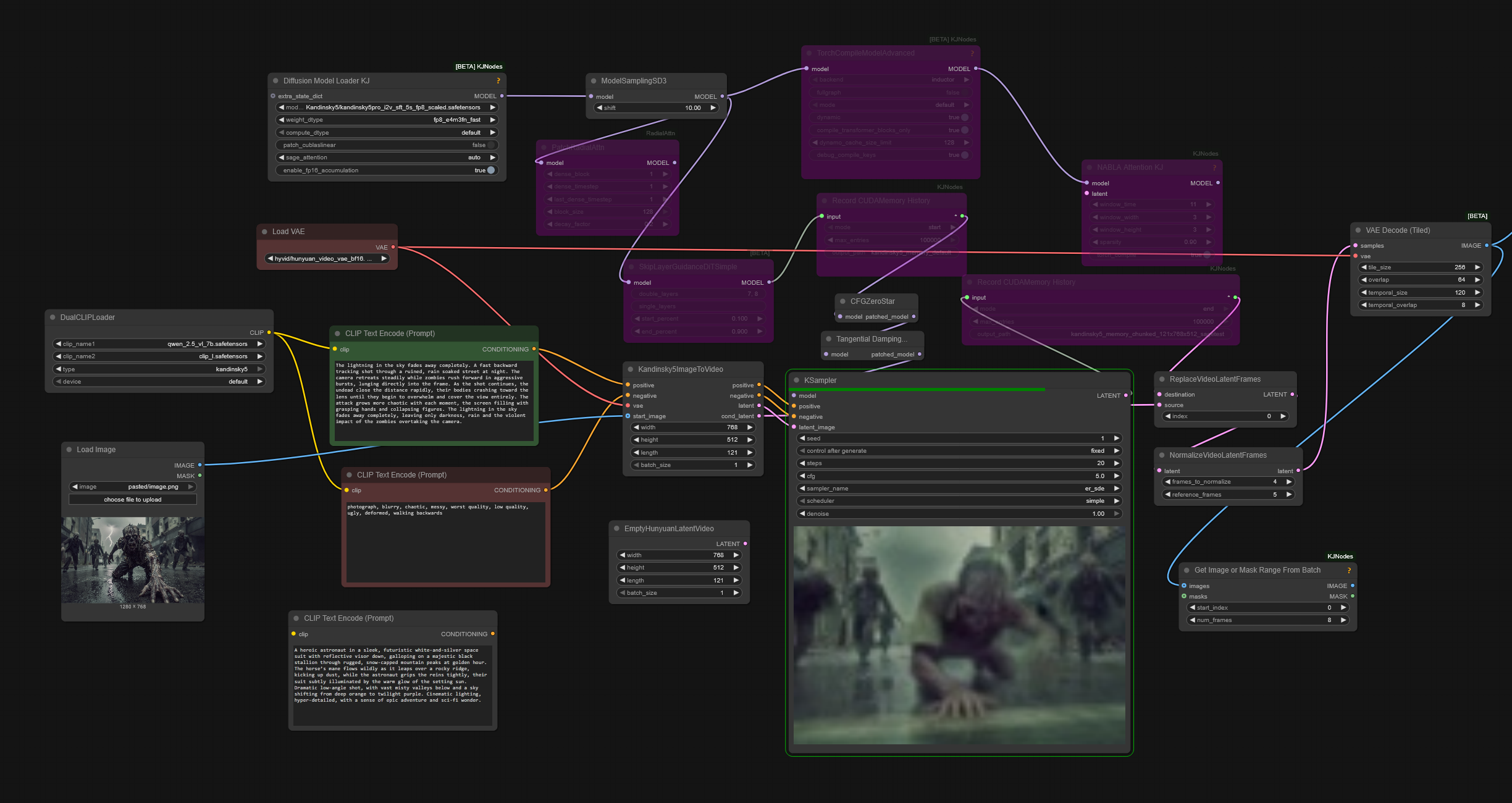
Kijai’s PR to add Kandinsky-5 support to ComfyUI native has been merged in
Presently there are just two nodes in ComfyUI which have are used exclisively by Kandinsky-5 workflows:
ClipTextEncodeKandinsky5Kandisnky5ImageToVideoKijai’s wip wf.
DiT-Extrapoloatin formerly known as RifleX is partially implemented for Kandinsky-5
that’s how the model works for I2V, the first latent is just noise and it has to be replaced by the actual input image before decoding
Experiments with running the model in ComfyUI on consumer hardware are in their initial stages. There currently exist two work-in-progress implementations:
Experiments suggest it is possible to generate longer than 10 sec clips, say 15 sec without looping or obvious quality problems.
some parts of the model need to be kept in fp32, the norms and embeddings etc. This is the mixed i2v model: https://huggingface.co/maybleMyers/kan/blob/main/diffusion_pytorch_model_i2v_pro_fp32_and_bf16.safetensors
kijai/ComfyUI-KJNodes contains NABLA Attention KJ node: “only useful if you go 10s or high res”; “Docs mention NABLA dimensions must be divisible by 128”
“Flex attention” is mentioned as an alternative (?) to Nabla.
Kandinsky-5 is using HunyuanVideo 1.0 latent space and VAE.
{kind=link}