wanx-troopers
Dialing In LTX 2.3 Workflow
Main article: LTX 2.3
2026.05
Nekodificador on avoiding blurry mess instead of motion
changing sigmas helps a lot try karras or exponential at least on a second pass
Nekodificador
i’ve noticed that it benefits a lot from high sigmas in the first 5-6 steps; simple and bong_tangent works really well
huddadudd, on the setup that allowed generation of nice turning humans:
exponential/etdrk2_2s clownshark 8 steps
huddadudd, on his latest wf
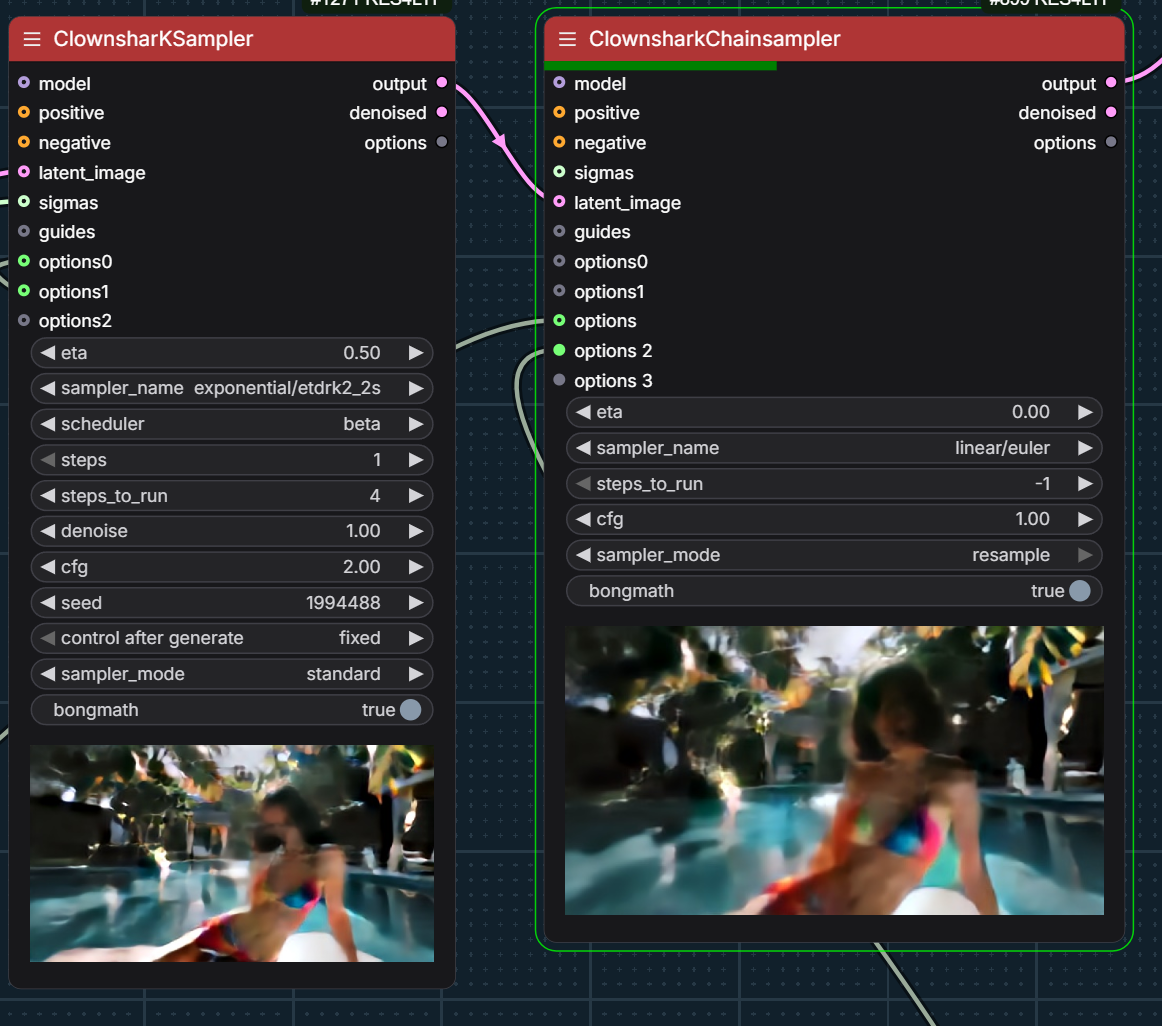
its mainly just 2 stage dev/distill, 1st stage distill .3-.4ish, second stage .5-.6; 1st stage i run 12steps 4/8, etdrk2_2s is good for motion fidelity i’ve found, qin zhang 2s can help with 2d stuff
“4/8” means 4 steps with ClowsharkKSampler on exponential/etdrk2_2s and 4 steps with ClowsharkChainSampler with linear/euler:
huddadudd-clownsampling, huddadudd-sigmas
Q: what does skipping the double layer 28 help out with?
[huddadudd] A: abel jones had recommended it a while ago, not sure if worthwhile but doesnt seem to hurt
David Show renders widescreen 1920x768
Fredbliss’s fork of SageAttention aiming for better performance on 4090 and possibly other cards
GH:fblissjr/SageAttention-ada. Works for sm89/sm90 + cuda 12.8 or higher.
Repository also includes some nodes which are mostly not needed outside of performance measurements,
skip_under_seq_len being “bypass int8 quant for small-Q calls (~377 token text-encoder shapes)”.
Associated wf: fml2v_aggregate_2026-05-13.
N0NSense’s idea on quicker refining with LTX N0NSense-LTX-refiner:
we feed the finished upscaled video, set it to 50 fps (film/rife), run it through a regular sampler with four steps and manual sigma, and then return it to 25 fps after the decoder (VHS node “Select Every Nth Image”). It feels better than a regular upscaler, but worse than the original 50 fps. The benefit is that it’s MUCH faster.
SantaHunter:
i’m getting interesting results (in a good way) with this, but as someone who is completely clueless when it comes to sigmas … 1st pass: bf16 dev checkpoint + 0.3 strength distilled lora 20 steps 1.5 cfg on 1st pass, euler_a; … runexx wf that is usually 8 steps for 1st pass, 2nd pass remains unchanged
I spent two days testing all the ones and ended up on euler_ancstral with lcm as fall back but thats on ltx for v2v mostly
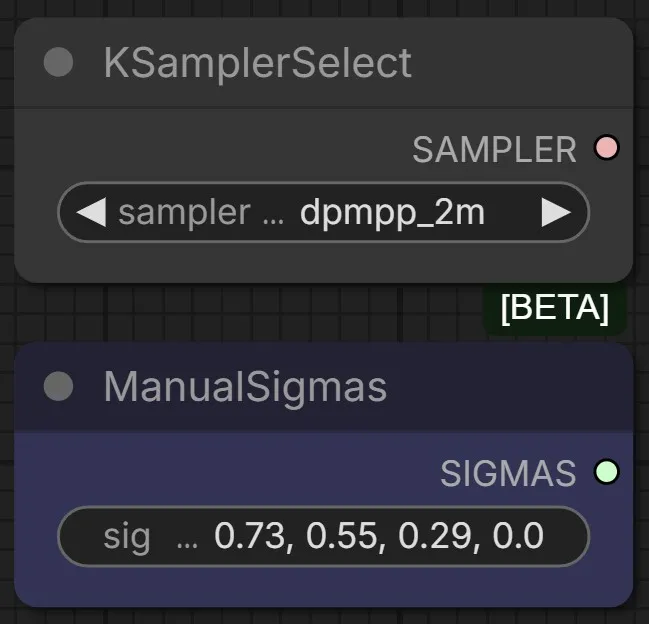
N0NSense experimenting with upscaler-experimental-settings dpmpp_2m, ManualSigmas 0.73, 0.55, 0.29, 0.0
The sigmas are chosen so that the details don’t change much after a lowres pass. But the most important thing is the sampler. It looks almost identical to the default euler_cfg_pp, but it’s twice as fast. need more different tests, so welcome.
2026.04.27
1.1 distilled in mxfp8 which seems good
Q: in ltx [does] using varying models of gemma affects the output? A: between the fp8 and bf16 versions, it’s minimal difference
Dev + the Distill LoRa 1.1 seems better than Distill 1.1.
Q: why would the dev + LoRa be slower? A: because you can’t apply lora in fp8 it has to do the upcast to apply, then downcast to fp8 to do the matmul; a checkpoint with the lora applied at half strength would probably be useful; … when you use fp8 checkpoint + bf16 lora, the lora is higher quality
David Snow:
if you use the distill lora on a second pass using a negative weight, it reduces the plastic skin greatly. so when using it for upscale set strength to a negative? Yeah. -0.4 is a good starting point.
huddadudd:
I prefer sampling to high frame rate and even resolution, i do most of mine at 1536x832
in post i clean up with a neat video pass
2026.04.24
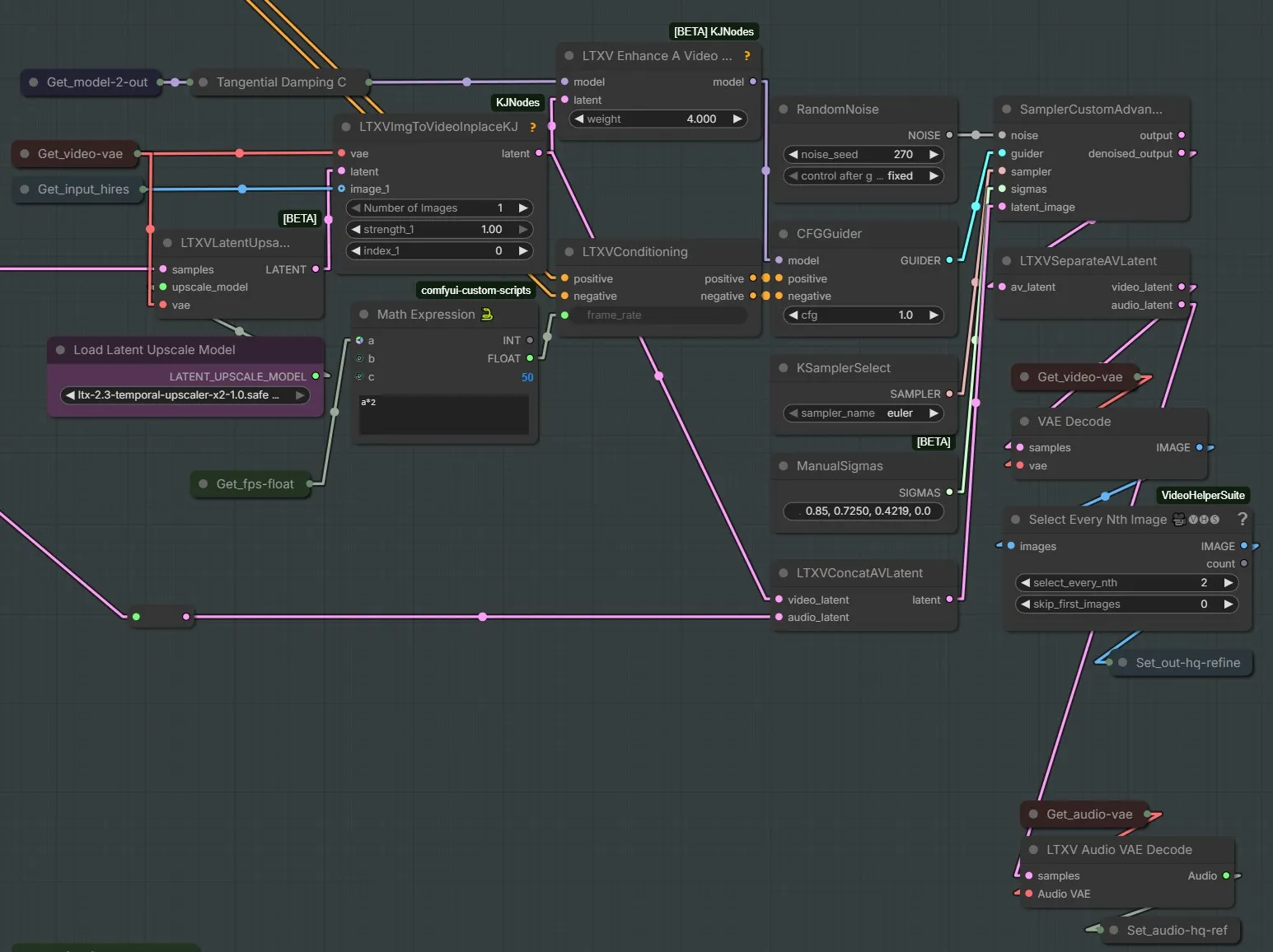
Ckinpdx on GH:ckinpdx/ComfyUI-LTXAVTools:
My looping sampler needs work to handle a second pass but the standard looping sampler can do it. Drop down the ltvx looping sampler, I use simple guider, res2s sampler and basic scheduler with beta 2 steps
.37denoise. I also recently added a tiled latent upsampler as I was getting oom at that part of the process. If you have a recent pull of my nodes it’s searchable with “tiled upsampler”. You can give it the full AV latent, don’t need to separate the latent going in. You do need to separate the latent going into the ltxv looping sampler though, only send video in and send the audio around it to final decode. In my v2v any to real wf i just replaced that lora with the edit anything lora … it did work.
Advice from Torny on how to get sharp videos out of LTX 2.3:
forget T2V (it is frustrating) go with I2v use latest kijai distilled model, 2x ver 1.1 upscaler, any of the latest Runexx workflows
2026.04.18
Huddadudd answering on how a good detailed 1536x832 3sec 25fps clip with a nice face in the distance:
i’ve been cobbling and updating my clownshark wf for a while now, its a hodgepodge of outdated and new stuff that i just tinker with; currently its 4steps gauss legendre then euler 8 steps, 2nd pass is eulerancestralcfgpp just a basic sampler; run the dev model, .3 distill lora first stage .5 second stage; thats also without any of the uprez or refinement passes; zimage is the image, just standard sampling, clownshark is stage 1, which is the bulk of the sampling; i mostly just modify versions of able’s workflows
pretty standard as far as generation parameters, one stage, dev w/ 0.6 distill, euler, linear quadratic 8 steps
Manual Sigmas
David Show: 1.0, 0.995, 0.99, 0.9875, 0.975, 0.65, 0.28, 0.07, 0.0, “it’s a three stage workflow, but those new sigmas are just being used on the first pass.”
Reddit post.
Q: do the manual sigmas have to be the default in the LTX template?
A: not really, it’s just a linear quadratic schedule
main thing is that with the distill you want it heavy at start, which linear quadratic is, so high shift
BNP4535353 found that for a large scale complex image of a moving sailing ship
default 8+3 step WF is far from sufficient, and at least 12+6 is needed BNP4535353-sailing-ship-sigmas BNP4535353-sailing-ship-sigmas-2nd It really resembles the Sigma pattern of Flux2: a straight line followed by a sharp drop
huddadudd: “the linear quadratic advanced node works pretty well also”
linear quadratic is literally the default (for distill)
BNP4535353
If the scene is a distant view or the objects are small in proportion, increasing the number of steps can directly help. However, if it’s a close-up, it will create a burning sensation similar to increasing the number of steps in a CFG scene. Overall, the default scheduler is fine. I’m currently testing different samplers. It’s difficult to find a universal set of rules for LTX. For me right now, 1920 1080 resolution with two stages + 50fps is the basic approach that can initially ensure no strange results. And setting OmniRL [OmniNFT] Lora to 2 seems to have become standard practice, as it increases LTX’s intelligence.
Samplers
res_2s is good with teeth
res2s is good for quality but also handles higher fps better … i started out with eulers, then lcm, then settled on res2s; the manual sigmas describe 3 steps, which works for euler in the second stage but is too many for res2s. for the second stage to use res2s without overbaking i use basi scheduler beta 0.34 denoise 2 steps. i run dev with distill and drop the distill down to 0.5 from the standard 0.6 in the second pass
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hevi:
lcm for first stage much faster than anything else imo
res_multistep might be better for sound generation than euler with distilled.
PhoenixRisen:
Seems euler_ancenstral_cfg_pp is the best for prompt adherence; [Mark]: runs like a dog on mine so I dont go near cfg_pp version
Mark:
I switched to euler_ancestral recently was using lcm but find it best in the wf I use.
huddadudd:
euler ancestral? that adds its own random noise because its a stochastic sampler [so keep seed fixed no longer keeps generations repeatable]
cfg_pp Samplers
cfg_pp also known as cfg++
fyi: any of the cfg_pp samplers will always run both a positive and negative conditioning pass even on cfg 1.0. So if you’re comparing euler_ancestral at cfg 1.0 to euler_ancestral_cfg_pp at cfg 1.0, the latter will always be 2x slower
Mark:
its way more than x2 slower on my rig … … it runs … NAG as well so would that mean it is x4 slower? (audio and video conditioning in NAG)
NAG is definitely not going to be as much extra compute as CFG since it only operates on cross-attention; CFG is literally just twice as slow, it runs two fully separate calls at the same step. Also, I dunno if NAG even runs for the negative pass
Clownshark Sampling
If set up identically the clown samplers should be exactly the same speed as the native samplers. But there are a few very non-obvious gotchas that can slow things down especially when you are only running several steps.
The extra options that I usually recommend actually just take out a bunch of additional steps that Clownshark Batwing added in to try to improve the accuracy of the generations on top of everything else, it’s literally stuff like “use a heavy sampler for the first 2 steps” and “add one extra step at the very end to denoise that tiny little extra bit”. These things are negligible for image models where you are doing 30 steps, but when running a video model with 8 steps they can make it very slow for very little benefit.
if you set the clownsampler up to run euler/ddim with nothing else added in and typical eta levels, it absolutely should just be the same as running native euler sampling
res_2s is going to be double the time because it literally runs two steps for every one step, res_3s runs 3 steps for every 1 step so it’s triple the time.
huddadudd:
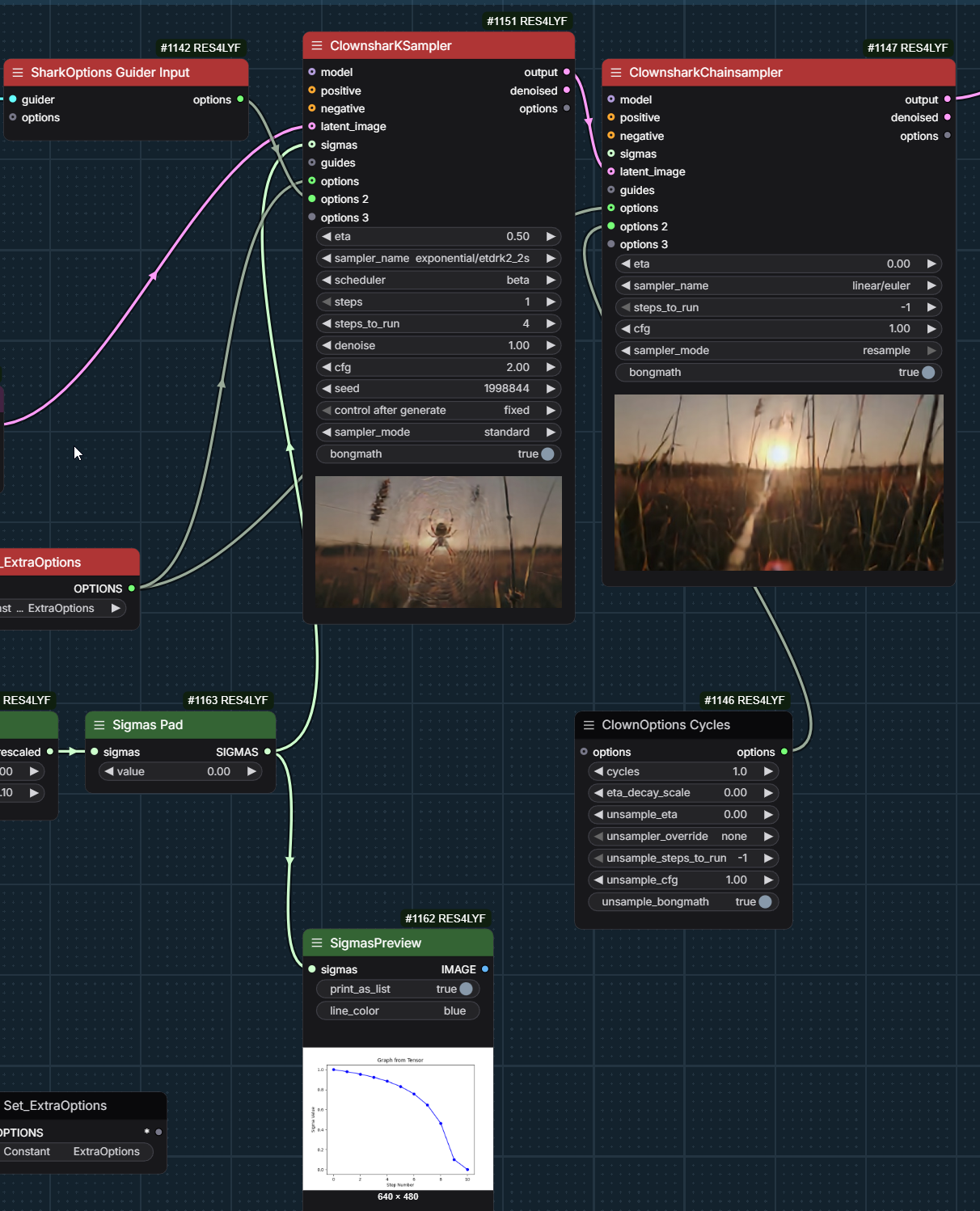
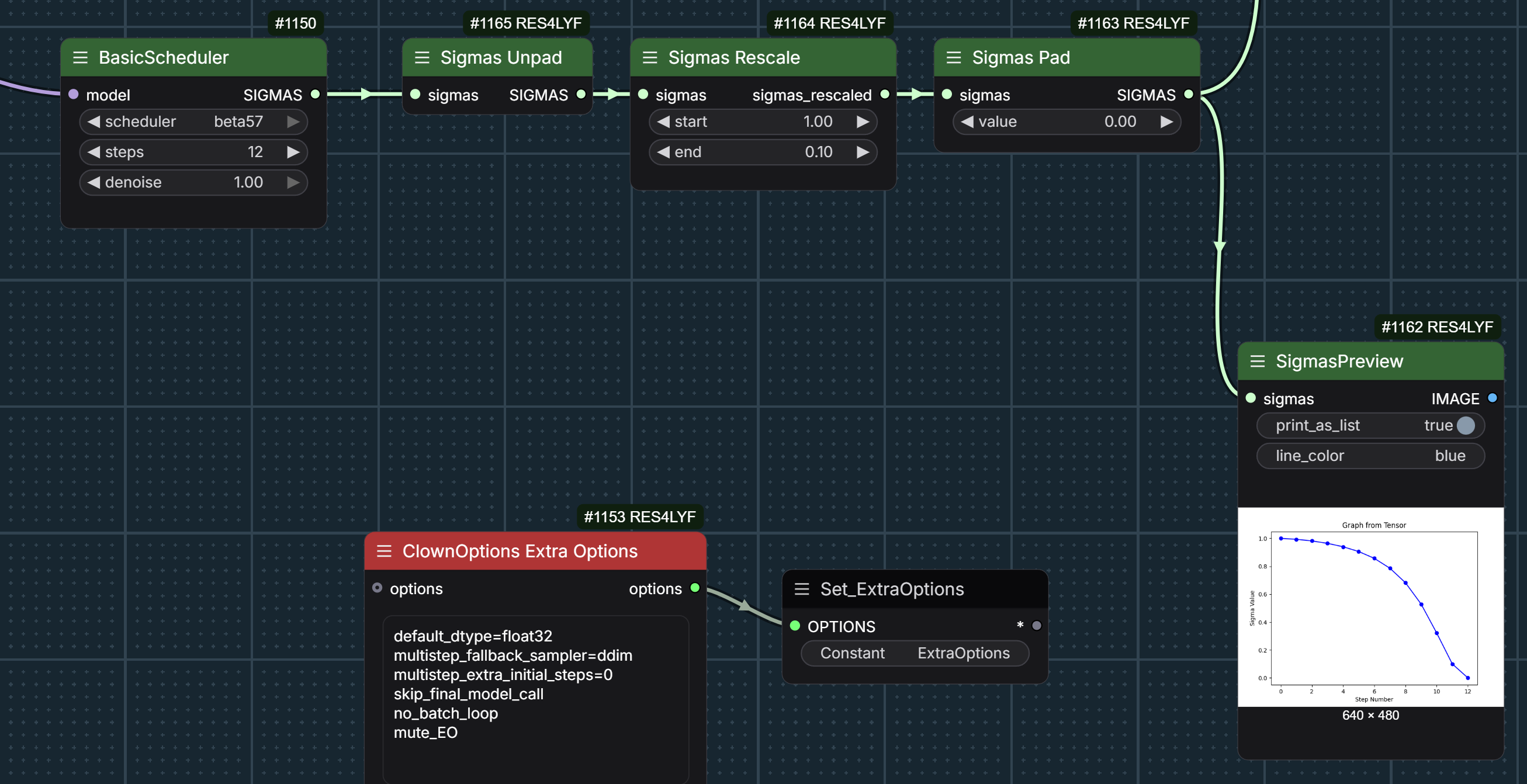
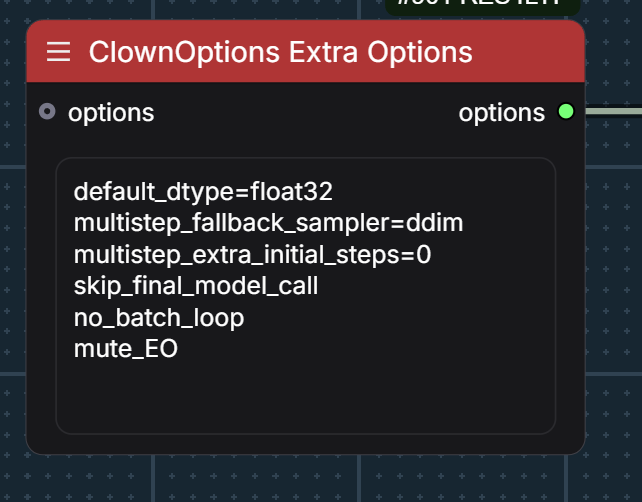
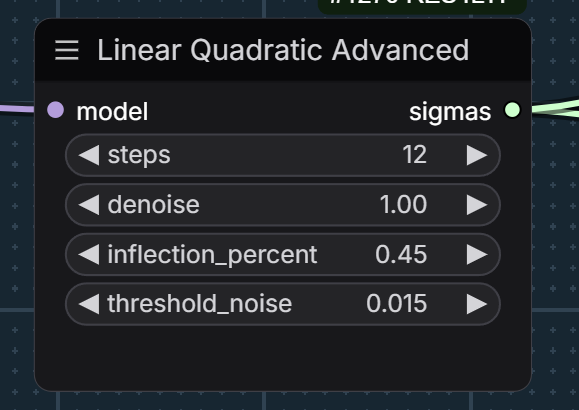
give etdrk2_2s a spin in the exponential set; I only use it for the first 4 steps of the initial chain sample .. I do 12 steps first stage, 4/8 huddadudd-clownsampling have these extra options huddadudd-chain-sampling-options /and these sigmas: huddadudd-chain-sampling-sigmas sampler one is using a sharkoptions guider and the 2nd chained sampler has a rebound cycle, but not sure how impactful the later is … 2 stage … last stage is 4 steps just simple sampling
{kind=link}
{kind=link}
{kind=link}
When asked for WF huddadudd pointed to Drozbay’s LTX 2.3 ClowShark workflow: droz_LTX-2_SharkSampling_v7.1
{kind=link}
Huddadudd’s Clean WF
The main variables i tweak in the setup is the sampler for the first steps (can be 2 or 4 steps based on 10-12 total) the inflection point on the quadratic noise, resolution on output, sometimes fhd is better sometimes 1536, then there is the second stage sampler which is less a factor but there is 3-4 options, but i’m sure thats standard for you as well. i avoid using any ltx loras outside of distill at .4/.6 str
chainsampling is the obvious powerful tool; there are different samplers that work for short quick actions better; there are ones that better for wide angle small size details; it’s all just incremental improvements that can stack
1546x832/ 25fps pretty quick gens (under 1.5 -2mins) it locks in on lvl of detail pretty well no loras or refining
Sequence
Mark’s way is: 1st sampler - temporal 2x - 2nd sampler - spatial upscaler