Main article: LTX 2.3
Huddadudd: “playing with stuff like this. the stg and modality scaling” “the stg values might help with the messiness and the strength of the effect”
Nokodificator: “BTW, if you wanna use advance controls like STG in the multimodal guider, you need to replace the stg.py from LTXVideo nodes with this one, otherwise you can’t use NAG or STG” stg.py
David Show: “I am using the lora loader advanced, with audio and audio to video set to 0, but that’s about it.”
N0NSens’s way to write a prompt with prompt relay for LTX 2.3:
A woman turns around, walks to the driver’s side door of the blue pickup truck. | she grabs the chrome handle, opens the door. | she places her left foot on the footrest and steps inside. | She sits behind the steering wheel and starts the loud engine. | the truck drives forward (to the left) out of the frame. Exhaust smoke comes out from the pipe behind the truck and dissipates in the rainy air.
Gleb Tretyak: “Am doing something wrong or is it true that ltx REALLY struggles with 2d anime?”
A: it does struggle for sure
coctailprawn1212:
I’m using fp4 mixed ltx by hippotes (seem like nvfp4)
Node to help select LTX resolution: GH:WepeNerd/ComfyUI-WepeNerd
Fred Bliss on LTX 2.3:
… instead of prompting alone, you can use audio to drive the scene. As an example - try just narrating a scene and using that as the audio and an init image and you’ll get fun results. Gemini Omni/veo can do it much better, of course, but the same concept.
GH:TenStrip/10S-Comfy-nodes some vibe-coded nodes including tiled sampler. Claims to be solving face consistency problem, YT ad: YT:Ikh5EZu8LNQ
Mark DK Berry: how are you stopping everyone else from mouth moving?
RuneX: often plenty to just be very specific in the prompt. Like “person number two (woman in white top), is talking and she says……”
might work with mask … Sam3 to mask the person … LTXV Set Video Latent Noise Masks
Fredblis: By freezing the audio mostly and using keyframes.
N0NSens:
Static camera shows A black woman in a leopard print dress, a man in jeans, a woman in a blue dress, and a woman in black pants and a leather vest (left) are chatting near an elevator in a hotel lobby. All characters are standing in their seats and remain in frame. The black woman in the leopard print dress says seriously, “Okay, let’s count. I’m first,” and looks at the man in jeans. | The man in jeans cheerfully says, “Okay, I’m second,” and glances at the woman in the blue dress. | The woman in the blue dress says calmly, “Well, then I’ll be third,” and thoughtfully examines her manicure. | The woman in black pants and a leather vest (on the left) says disappointedly, “Well, of course! And I’m naturally last…” She frustratedly puts her hand to her forehead and shakes her head in disapproval.
… well.. it was clownshark, maybe that’s the case
Mark DK Berry: okay so new discovery with my 4 person dialogue situation, it isnt the prompt or the sampler causing the issue, it is the fact I am not giving the woman on the left anything to do because the woman on the right has two dialogue moments, so woman on the left is just mouth cloning the blue dress woman’s prompt segment
… it was the loras after all … I disabled them … got the correct results … VBVR, OmniFT and dual character loras disabled was beneficial … having them in was amplifying occurances of that mouth cloning issue. … wonder if its because they probably havent been trained on more than 3 people
re upscaler re-introducing the issue:
lcm fixed it; the lower manual sigmas worked even with euler_ancestral
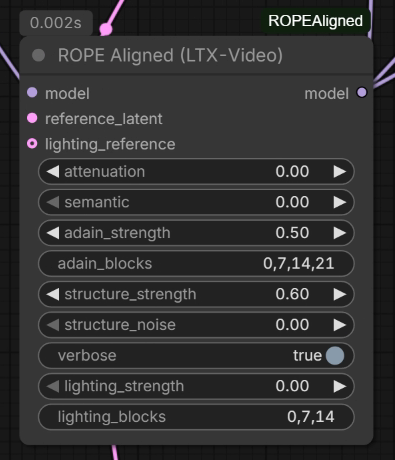
LDWorks David playing with ROPEAligned, adain: LDWorksDavid-ROPEAlighed-adain
“for now Im more involved into the structure rather than lighting, I know I can ref a image as lighting latent and pushing specific blocks (0,7,14) for global/exposure lighting, problem is when we are not talking about T2V”
Q: are you guys getting like a dot/grain pattern? A: that’s not from the HDR lora, that’s what happens if you don’t use upscaler [Richard Servello]
Q: is the ltx spatial upscaler not supposed to be sharp? A: if used correctly it’s very sharp
PhoenixRisen:
motions seems to be accurate in the early steps but by the time u get to step 8 a lot of that motion is greatly removed. Like somebody walking seems more fluid in the early steps, walking seems much dulled down by step 8. I am using distilled saftenors 1.1. I noticed increasing the cfg to 2.0 helps.
Zueuk on LTX audio latents:
latent cut; y axis; which is unobvious; LTX Add Latents can combine them, but only if none -or- both of them have mask, otherwise it fails
Ckinpdx on LTX Audio Latent Trim node:
I added a strip mask to the audio latent trim to address that
Richard Servello:
LTX union ic-lora was trained on a distilled sigma schedule. So you have to use their exact gradient for it to work
LTXV Chunk FeedForward (for low VRAM) - “don’t touch the chunk size, it’s mostly testing param and in practice 2 is enough”
“it chunks the feedforward layer (ffn) calculation, doing it in 2 chunks already puts it below other VRAM peaks
and default non-chunked is a huge spike that can be multiple GB of higher peak VRAM at larger inputs”.
grimm1111: “The v1.1 distill is a noticeable improvement. The details and coherence are improved. I typically run the distill model with the distill lora at neg 0.2 or so. 15 steps, CFG 1; Also I only ever do single pass, that’s just me. And no temporal upscale or anything like that. my favorite aesthetic is “movie shot in the 1990’s” so I don’t really go for the super HD stuff. I like the softer analog camera look over the super-digitized look”
distill 1.0. I feel the colours are a lot more natural. maybe just a saturation node will be enough.
mamad8:
Using split sigmas with the distill Lora (strength 0.5) to set cfg 2 for the first 2 steps and cfg 1 for the remaining 6 steps helps A LOT, especially audio but also overall coherence and motion”
distill 1.1 as lora str 0.6 and just works
{kind=link}