wanx-troopers
Hints On LTX 2.3
2026.05
X:2054900232693973279 controlling LTX 2.3 animation with voice.
Yi:
One thing I found is including “A movie scene shows” before a prompt greatly reduces the chance of body morphing
Jonathan GH:WhatDreamsCost on fixing an issue in a video with LTX 2.3:
a few ways off the top of my head
- you could mask the hand in black, use the outpainting ic lora to inpaint the ghost limbs away
- you could use try using the edit anything ic lora and either use a mask with it or just try prompting it away
- you could grab the first frame the ghost limb appears, edit out the ghost limb in klein or simply photoshop it, and run v2v with ic lora
Q: Which IC LoRa you think might help to fix issues like this? UnionControl? IC LoRa wf without a LoRa?
A: both, try without control net first and if it doesn’t match the motion good enough then try using like a depth map at a low strength
Try putting a clear vram node before both of your decode nodes, I had a similar issue of the audio decode taking sometimes minutes to complete even on short videos. Now it’s almost instant.
huddadudd:
I’ve found that ltx plays well with some lensing and barrel distortion
ltx is banning adverbs form the llm prompter; got much better prompts after removing the crutch
2026.04.29
Q: how do I get LTX 2.3 not to generate music?
A: do you have any audio description in your prompt? you could try describing only what you want to hear, or just something generic like “ambient sounds”, also NAG prompt with “music” has sometimes worked for me, music seems to be a default the model goes to when there’s no audio descriptions
Screeb:
something like “Audio: ambient sound” at the end of the prompt almost always works (and still allows speech)
PineAmbassador:
try “raw foley” in the positive prompt, and “music, cinematic riser” in the negative. also maybe raise your CFG so it’s following your prompt more
Before 2026.04.29
Latent tokens in a video: (Width / 32) × (Height / 32) × ((Frames - 1) / 8 + 1); might be best not to exceed 20-35k without looping/context windows.
As long as the video is relatively static, it’s amazing. As soon as there’s fast motion … [things get mushy]
The newer ic Loras like the union one are trained with half res. Latent downscale factor? Yes.
Vertical format videos may still be more problematic than horizontal ones, even though it was claimed they were fixed in LTX 2.3.
Lower image compression (16) helped with a crazy-looking person (no eyes) where higher compression (22) failed.
N0NSense is generating cool videos using
- cinema4d playblast render
- AIO Aux Preprocessor
- depth map
- IC LoRa
Above is also possible with LTXVImgToVideoInplaceKJ node to also use FLF.
N0NSense: emptying a glass is a practically impossible task for the model in i2v mode. The only option is FLF.
Also tested with: Draft animation + hard cuts. depth, IC str 0.4, clwn sampler, t2v.
“Need more detailed prompt for camera movement but seems to work”.
Can be used to lock camera static: N0NSens-static-cam-ltx23.
“ic union lora. depth” “it’s based on LTX-2.3_ICLoRA_Union_Control workflow from ltx”
It is sufficient to place cubes where characters need to be and they can be rotated to make characters look the right way etc. This also covers scene cuts.
“depth at str 0.2”; “i2v, using starting image”; Q: why not render depth? A: don’t want to spend time for rendering from c4d; … visible wireframe helps to detect some depth by depthAnything
Recommended ic guide strength: 0.1 - 0.4 for depth, 0.2-0.6 for canny, 0.5-1.0 for pose; lower strength allows ltx be more imaginative
Making of “Gloomy Bukur” Vasily Bodnar, N0NSense
… a … (left) does this … a … (right) does that. the camera abruptly changes angle: the … is on the left in the background … the is on the left in foreground …
Change FPS from 24 to 25 to fix de-sync of audio
Mark’s Workflows “LTX 2.3, 10 seconds, 24 fps, 241 frames. I dont go over that, no real need. and I end on 24fps coz I like it”
Mark DK Berry: I’ve been experimenting with Phantom 1.3B running through USDU to add the WAN back in to LTX results. I am low VRAM so cant do 14B in under 30 mins, but 1.3B is surprisingly good and very fast even on low VRAM and manages 1080p 24fps, 241 frames in minutes fixing up some of that LTX detail issue like eyes quite well … anyone with a decent card should be WAN 14B detailing low denoise for polish and you’ll have perfect results from LTX. Juan Gea: Yes, Wan 2.2 14B is the perfect “last pass” for LTX, or the HUMO version.
Reported as working (empty lines are extra empty lines in prompt):
[fen] character description
[scene] scene description
[sound] ambience description
[0-1s] [fen] does … says “..”
are these 2 still needed? Yeah they still help
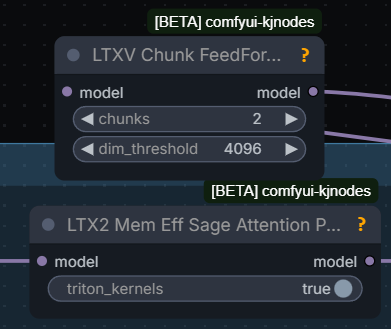
{kind=link}
Kijai’s tensor loop node “is just a utility” “it works but somewhat awkward with the audio length calculations”
GH:fblissjr/ComfyUI-AudioLoopHelper “super rough around the edges but if anyone wants. its meant to handle all those timing calcs that i didnt wanna bother with”
Q: when using a sampler for videos, what sampler would you suggest to use for clear and fluid animation?
A GH:vrgamegirl19: i found that these two seem to give good results. i would try them both euler_ancestral, euler_ancestral_cfg_pp
Hicho:
i didnt know that flf nodes accept video frames; is this how we do extension?
Two NAGs exist which can be used with LTX 2.3, “very different”, “whole different method of applying”
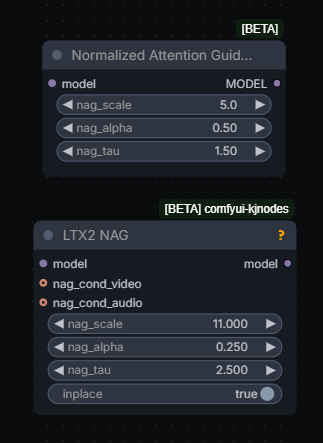
Can try APG Guider instead of CFG Guider to reduce color shift issues, article.
Do not put quotes around dialogue to avoid subtitles, also Kijai’s NAG.
[On AMD rdna2] ltxvideo works on fp16 even though it is not listed in comfy config file, and it is faster for me than fp32; nvfp4 also works for me but with that the quality is not that great
VAE Decode Tile needs temporal_size way above 8 to avoid flickering.