Image tools useful alongside video AI. Sometimes autogenerated sound can be of use too.
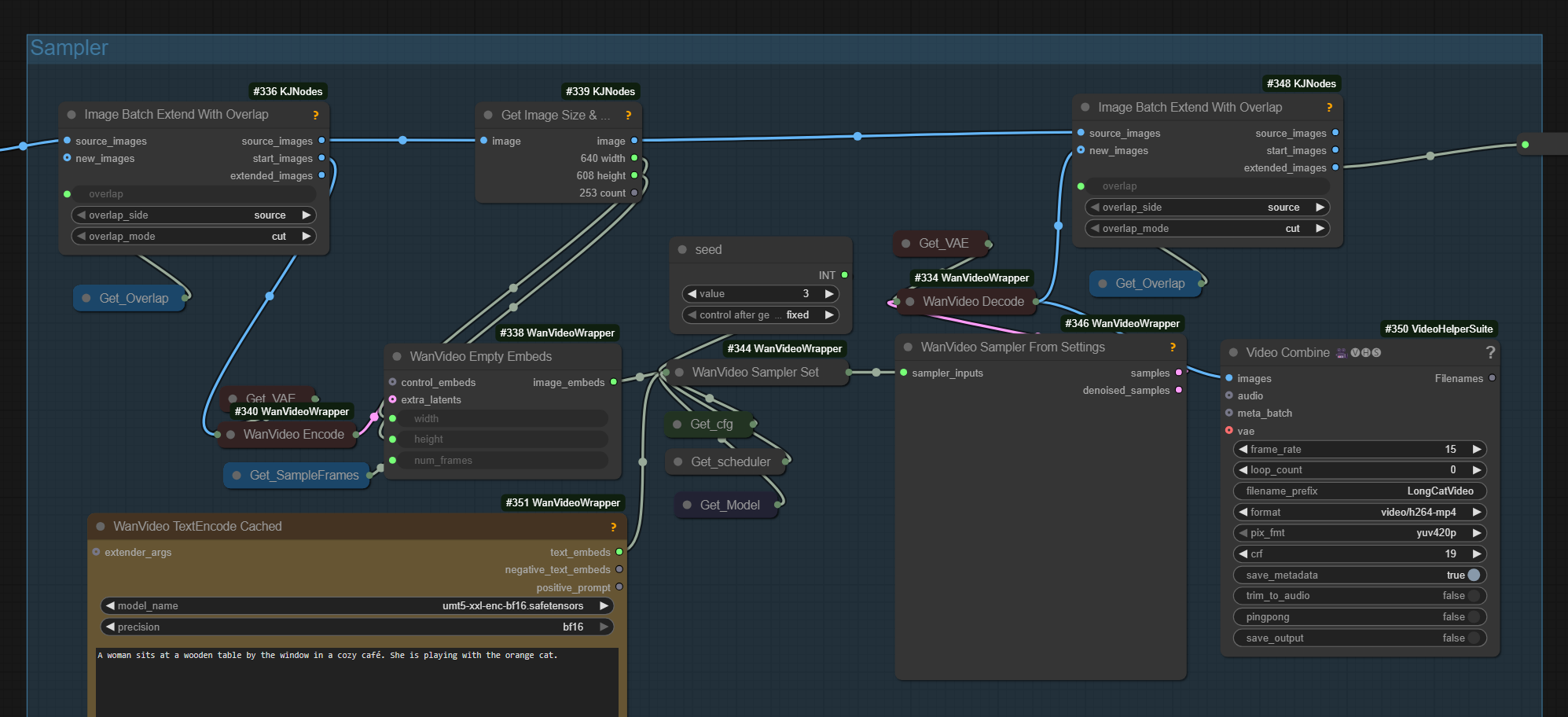
kijai/ComfyUI-KJNodes contains Image Batch Extend With Overlap
which can be used to merge together original video with its extension done using I2V or VACE mask extension techniques.
Example of it being used in a LongCat wf: extend-with-overlap.
WanVideoBlender from GH:banodoco/steerable-motion is an alternative.
6B Z-Image-Turbo introduced around 2025.11.26 is a distilled image generation model released under Apache license. Community is raving :) Model re-uses Flux VAE but appears not be based on Flux.
Model page promises non-distilled and edit versions to be released. “beats flux 2 .. at a fraction of the size … less plastic than qwen image”.
The stock ComfyUI workflow for z-image is quite traditional: Clip Encoder users qwen_3_4b to encode user prompt and feed it to KSampler.
The surprise is that Z-Image-Turbo had been trained on conversation sequences which have then been encoded by qwen_3_4b.
A number of projects have emerged to help take advantage of this. Most prominently there is GH:fblissjr/ComfyUI-QwenImageWanBridge. As the explanation says:
There’s no LLM running here. Our nodes are text formatters - they assemble your input into the chat template format, wrap it with special tokens, and pass it to the text encoder. The “thinking” and “assistant” content is whatever text YOU provide.
If using an LLM the project recommends using “Qwen3-0.5B through Qwen3-235B” because they also use qwen_3_4b and tokens produced by them are passed without re-encoding.
Then there are other projects which do make use of LLM-s to help generate the prompt. One is discussed here.
Supposedly has affinity to Wan models since both come from Alibaba.
| HF Space | Model |
|---|---|
| Comfy-Org/Qwen-Image-Edit_ComfyUI | split_files/diffusion_models/qwen_image_edit_2509_bf16 |
| Comfy-Org/Qwen-Image_ComfyUI | split_files/vae/qwen_image_vae |
| Comfy-Org/Qwen-Image_ComfyUI | split_files/text_encoders/qwen_2.5_vl_7b |
| lightx2v/Qwen-Image-Lightning | Qwen-Image-Edit-2509/Qwen-Image-Edit-2509-Lightning-8steps-V1.0-bf16 |
| lightx2v/Qwen-Image-Lightning | Qwen-Image-Edit-2509/Qwen-Image-Edit-2509-Lightning-4steps-V1.0-bf16 |
Generates 1st frame for next scene in same location with same character. Sample workflow on HF next to LoRA.
| HF Space | LoRA |
|---|---|
| lovis93/next-scene-qwen-image-lora-2509 | next-scene_lora_v1-3000.safetensors |
Text editing similar to Nano Banana (dataset visualizer, dataset)
| HF Space | LoRA |
|---|---|
| eigen-ai-labs/eigen-banana-qwen-image-edit | eigen-banana-qwen-image-edit-2509-fp16-lora.safetensors |
link - 4-step Qwen image distill
PuLID ?
github.com/phazei/ComfyUI-HunyuanVideo-Foley
| HF Space | safetensors |
|---|---|
| ComfyUI-HunyuanVideo-Foley | hunyuanvideo_foley_xl |
| ComfyUI-HunyuanVideo-Foley | synchformer_state_dict_fp16 |
| ComfyUI-HunyuanVideo-Foley | vae_128d_48k_fp16 |
Inside of Comfy you could Use Stable Audio or ACE… but tbh both are not that good
IndexTTS2: “I had Chatterbox, IndexTTS, another IndexTTS node, Chatterboxt5, VibeVoice … IndexTTS seems a lot better”
VibeVoice TTS
SuperPrompt node from kijai/ComfyUI-KJNodes.
Merge Images node from VideoHelperSuite (so called VHS)
Urabewe/OllamaVision a SwarmUI extension to generate prompts.
GH:chflame163/ComfyUI_LayerStyle can add film grain to images.
CRT-Nodes added LoRA Loader (Z-Image)(CRT). It can load zit-ivy.safetensors
Resize Image v2 from kijai/ComfyUI-WanVideoWrapper new mode is total_pixels copies what WanVideo Image Resize To Closest from kijai/ComfyUI-WanVideoWrapper does which is original Wan logicVideo Info from Kosinkadink/ComfyUI-VideoHelperSuite + Preview Any to debug dimension errors in ComfyUI etcImage Batch Extend With Overlapfrom kijai/ComfyUI-KJNodes to compose extensions created with VACE extend techniquesTo increase FPS: RIFE VFI still good to double frame rate with rife49.pth, can plug after stock Upscale Image By with upscale_method=lanczoc. Faster alternative suggested online: FL RIFE Frame Interpolation from GH:filliptm/ComfyUI_Fill-Nodes again with rife49.
{kind=link}